性能优化
1. 概述
性能,是指在本产品中工作的速度,它可以表示数据分析的速度,例如远程访问数据库并加载、转换数据时,可以感受到不同的数据库可能速度不一样;也可以表示BI平台中访问的组件或报告的加载速度。
影响性能的原因是多样的,为了提高性能,我们需要定位到具体影响因素,针对性地进行优化以便更好地调整报告,在不影响报告结果的同时提高性能。
2. 影响性能的因素
您在查看报告时,每一个图表背后的数据其实都是系统下发SQL去底层数据库查询得到的,大致可分为以下几个阶段:
- 首先是查询准备和组件推导时间,即BI平台需要知道查询什么样的数据、生成什么样的图表;
- 然后是在数据库执行SQL获取数据的过程(该过程的耗时很大程度上由数据源的性能和查询复杂度决定);
- 等SQL执行完,BI平台拿到数据,前端渲染绘制图表,进行数据的可视化展现。

以上不同阶段,无论哪个阶段“慢”都会导致最终报告加载慢,当然我们也可以通过一些针对性的操作来避免某些过程的“慢”。本文目的就是提供这类平台侧及数据侧的最优操作指南,帮助大家制作一份“性能更优”的报告。
3. BI平台侧优化
3.1 数据模型
同一个模型中关联的表越多,生成的查询SQL越复杂,执行速度慢,导致报告性能差,建议单个模型中关联的表不超过5个
3.2 报告制作
(1)单个报告页面筛选器和图表数过多
单个报告页的组件数越多,组件加载时间也就越长,建议单个报告页面筛选器和图表总数不超过100个。过多的图表可通过添加多个报告页进行展示,不同页面展示不同数据也更助于分析思路的沉淀哦~
(2)报告中存在未使用的模型,也会影响报告页面的加载,建议将无用的模型删除(数据医生的诊断功能支持一键删除)。
3.3 其他小技巧
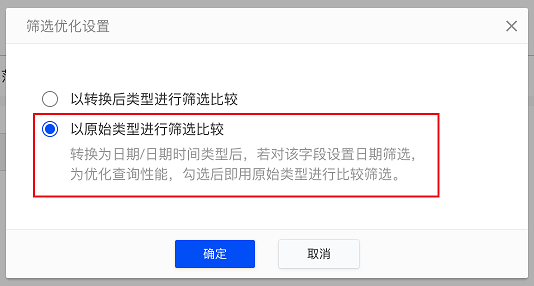
转换字段类型为日期/日期时间类型时,可选择用原始类型进行比较
将“字符串”类型的字段转换为“日期、日期时间”类型时,使用原始类型(即字符串类型)进行比较则不需要在SQL中进行字段类型转换,可提高查询性能。
例如:有「销售日期」字段,该字段的原始类型为:字符串,在模型/报告中将该字段转换为:日期。假如对「销售日期」字段进行筛选,筛选「销售日期」在2021年11月11日之后的数据,则SQL为:
TO_DATE(CAST('t1'.'销售日期' AS TIMESTAMP))>=CAST('2021-11-11' AS TIMESTAMP)若「销售日期」字段仍然为“字符串”类型,这个时候筛选「销售日期」在2021年11月11日之后的数据,则SQL为:
't1'.'销售日期' >='2021-11-11'可见,使用原始类型(即字符串类型)进行筛选时,SQL语法简单很多,查询性能也因此有所提升。因此设置日期筛选时,建议选择用原始类型进行比较。具体步骤如下:
(1)转换数据类型:

(2)筛选优化设置的弹窗中选择“以原始类型进行筛选比较”:
筛选器相关的更多优化可见:筛选器优化
4. 数据底表侧优化
如果您购买的是本产品私有部署版本,可参考此小节。
4.1 分区筛选
若您使用的是有数大数据平台impala数据源,则可以针对「分区筛选」进行优化操作。
使用的数据表中含有分区时,添加分区筛选则默认选中最近分区,只扫描指定分区的数据,不再扫描全表,极大提高查询性能。具体操作步骤如下:
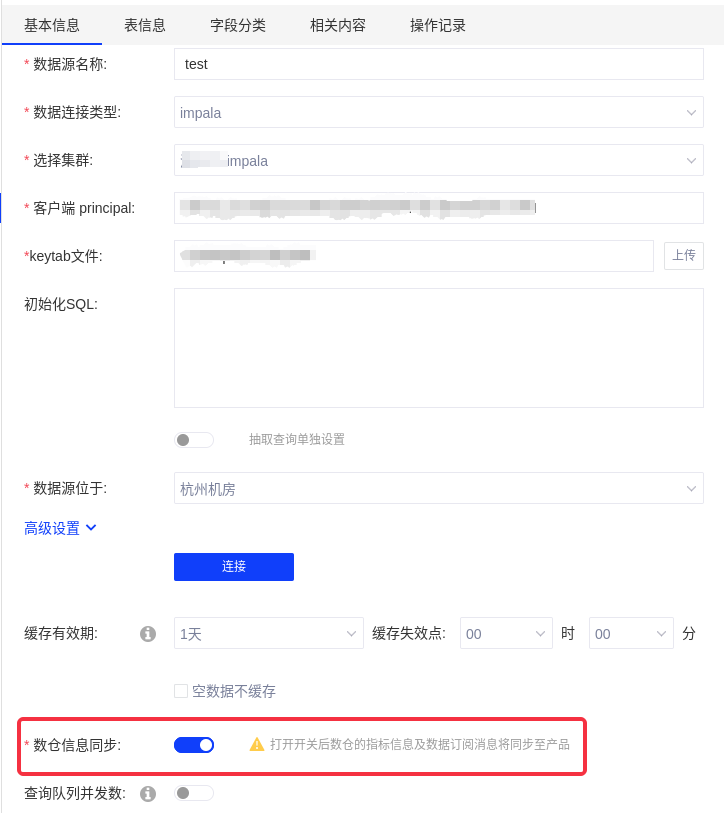
(1)数据连接开启数仓信息同步:
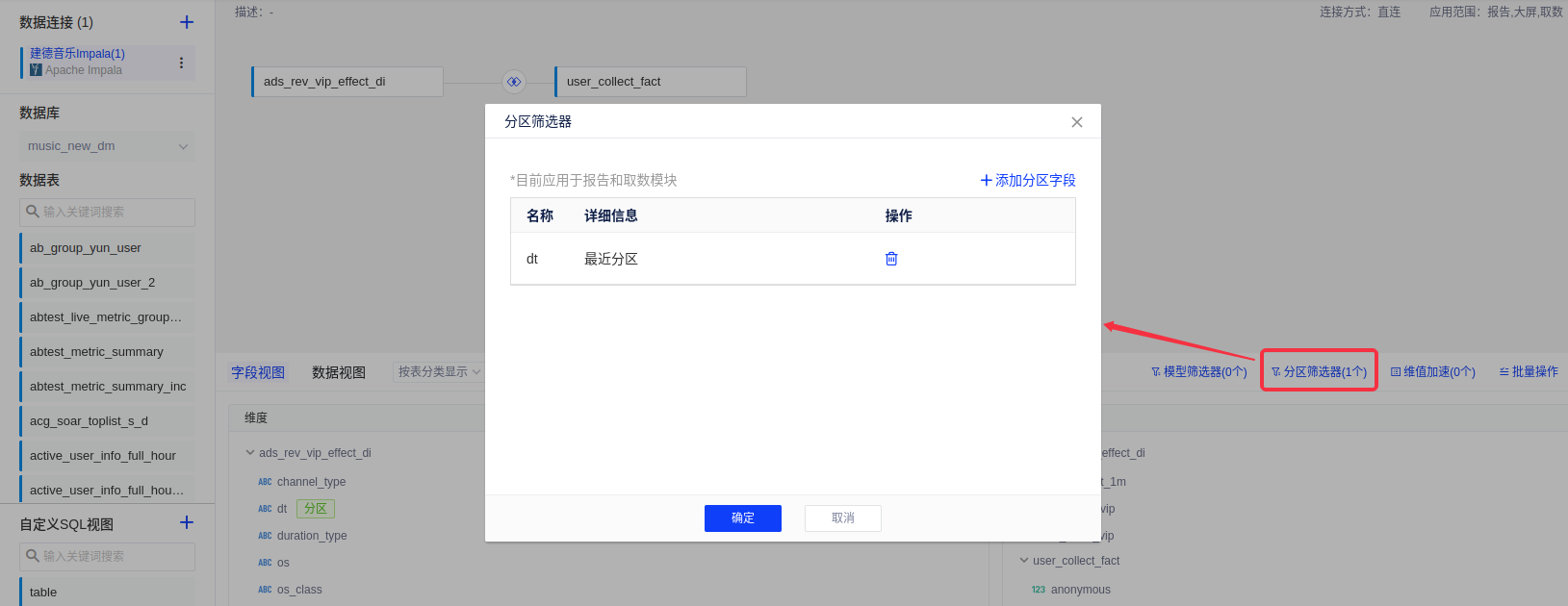
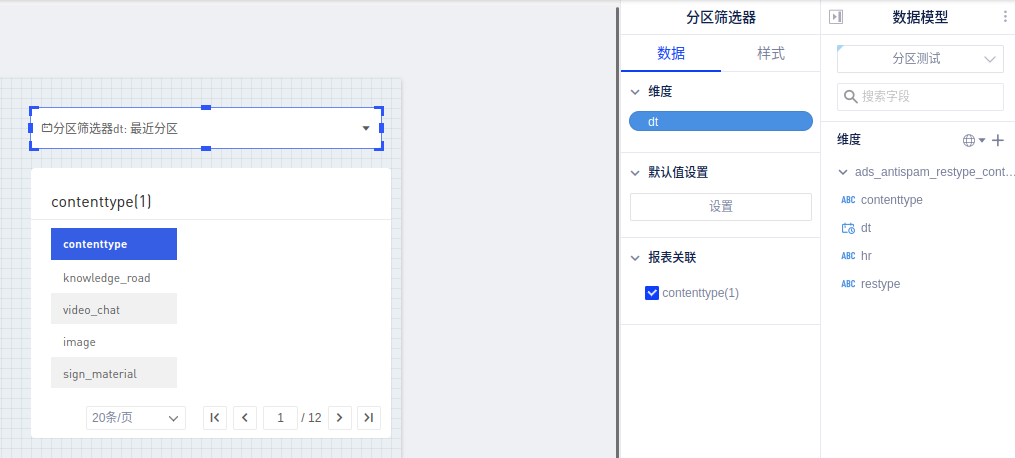
(2)模型侧加上分区筛选器:
(3)分区筛选器作用于报告时,模型中没有隐藏的分区字段,生成的图表默认带上该分区字段的分区筛选器并默认选择最近分区(若模型隐藏分区字段,则不会在报告上加筛选器):
4.2 使用Parquet存储格式
什么是Parquet存储格式?
Parquet为高性能列式存储格式,由于OLAP查询的特点,列式存储可以提升其查询性能。同时Parquet格式支持压缩,可以降低数据存储量,并且在查询时减少磁盘IO。因此使用Parquet存储可以提升其查询性能,从而提高报告性能。
具体操作
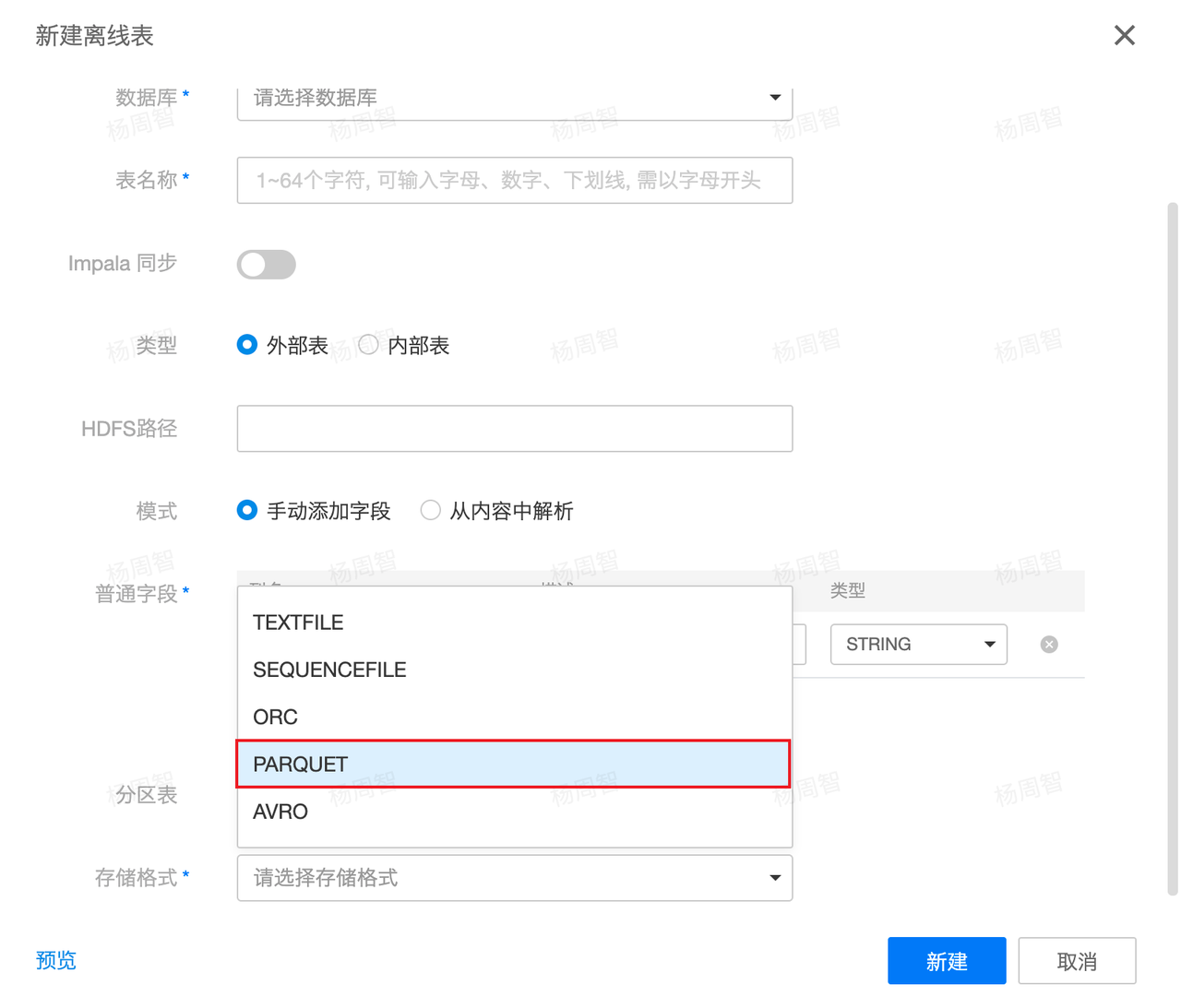
(1)在有数大数据平台数据管理中,新建离线表时,存储格式选择PARQUET
(2)使用SQL,在创建表时,使用STORED AS PARQUET
CREATE TABLE dm_some_hive_table (
some_field STRING COMMENT 'a field',
...
)
STORED AS parquet #存储使用parquet4.3 使用分区表
什么是分区表?
表分区是一种数据组织方案,在此方案中,表数据根据一个或多个表列中的值划分到多个称为“数据分区” 的存储对象中。每个数据分区都是单独存储的。分区表在查询时结合分区筛选,对于大数据量查询有较大性能提升,建议总数据量百万以上的表,尽量都用分区表。
具体操作
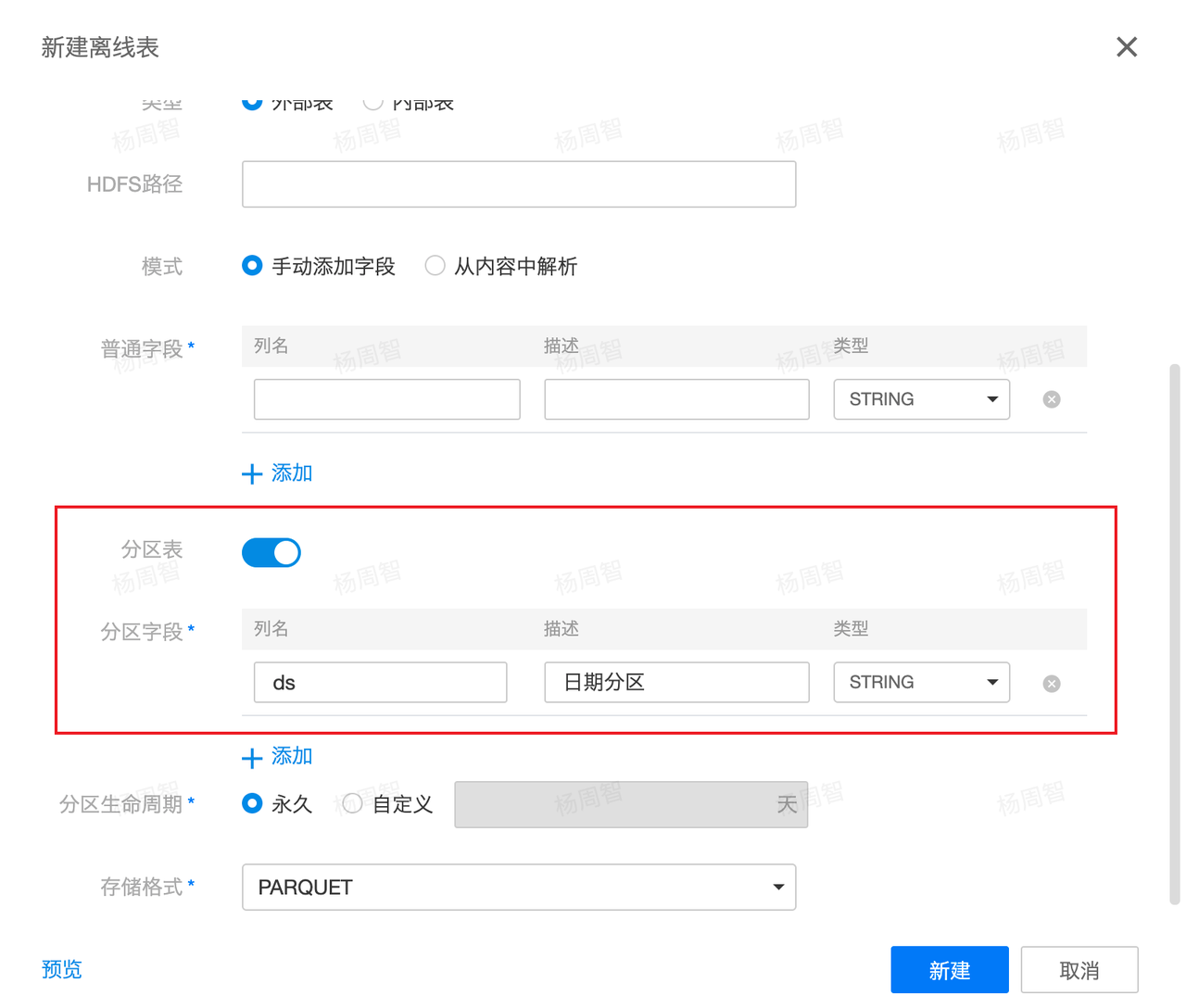
(1)在有数大数据平台数据管理新建离线表时,开启分区表选项,并设定分区字段
(2)使用SQL,在创建表时,使用PARTITIONED BY**
CREATE TABLE dm_some_hive_table (
some_field STRING COMMENT 'a field',
...
)
PARTITIONED BY (`ds` string COMMENT '按照天进行分区')
STORED AS parquet4.4 减少(分区)小文件数量
什么是“小文件?
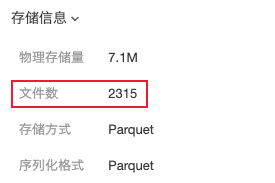
Hive/Spark等运行SQL任务,在将运算好的数据写回HDFS时,有时候会产生大量小文件,相关信息可以在表详情查看:
如果是分区表,则可以在“分区信息”看到具体分区的文件数:
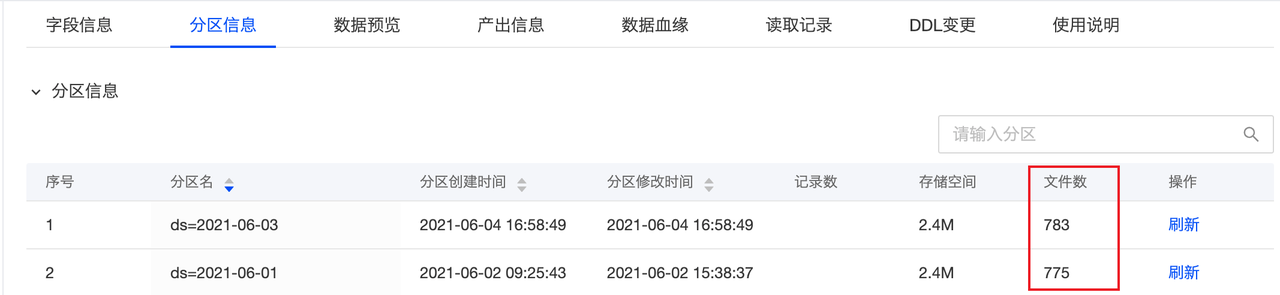
大量的小文件在查询时,增加元数据同步压力,也增加HDFS NameNode访问压力,尤其在并发查询稍多时,查询性能会直线下降且十分影响整个查询引擎集群的查询处理。
如何减少?
目前通常数据底表大多是离线表(T+1时效),每天使用猛犸任务调度执行。因此可以在任务末尾使用distribute by cast(rand() * 10 as int);语句,可以降低分区文件数量,对文件数过多的底表的查询性能有较大优化。
示例:
insert overwrite
table dm.dm_youdata_online_domain_kpi_info_p
partition (ds = '${azkaban.flow.1.days.ago}')
select
m.domain_id as id,
m.name as name
from dim.dim_online_entity_domain_content
left join (
select
domain_id,
visit_date
from
dw.dw_online_entity_domain_visit_record
where
ds = '${azkaban.flow.1.days.ago}'
) n on m.domain_id = n.domain_id
group by
m.domain_id,
m.name
distribute by cast(rand() * 10 as int); ###处理建议
- 代码片段中的10可以按需调整,一般如果单分区中数据量较大(相应存储量大)时,该数值可以增大,但不建议超过100;
- 在有数中使用的表的生成任务中加一下即可;
- 如果表本身文件数不多且无分区(例如维表)或历史分区中的文件数较少,则可以不用处理。
4.5 表统计信息
在有数大数据平台自助分析模块,对非分区表执行“compute stats”,分区表执行“compute incremental stats后面接分区”来添加表的统计信息。