准备数据
想要用自己的数据,需要项目管理员或模型编辑者在有数BI中提前配置好哪些数据模型可以在ChatBI中使用,然后项目管理员通过权限控制哪些用户可以查看这些模型。
最终用户在ChatBI中能够使用的数据模型为:被设置了应用于ChatBI的模型,且用户对该模型有查看权限。
1. 两步完成配置
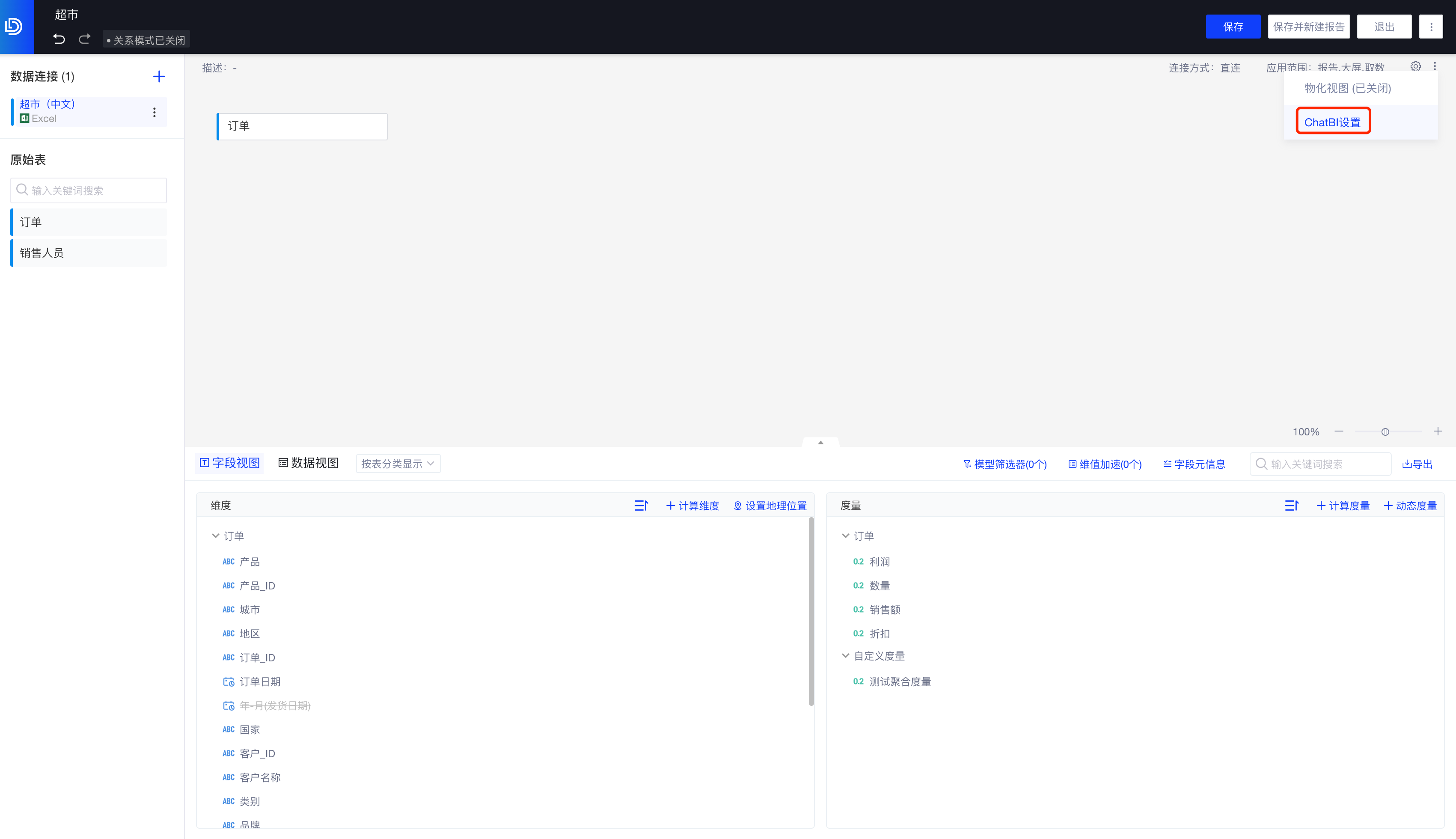
1.1 将模型打开「ChatBI设置」
项目管理员或模型编辑者进入数据模型的编辑界面,在模型「更多」操作按钮下选择「ChatBI设置」,并在设置中打开ChatBI的开关。

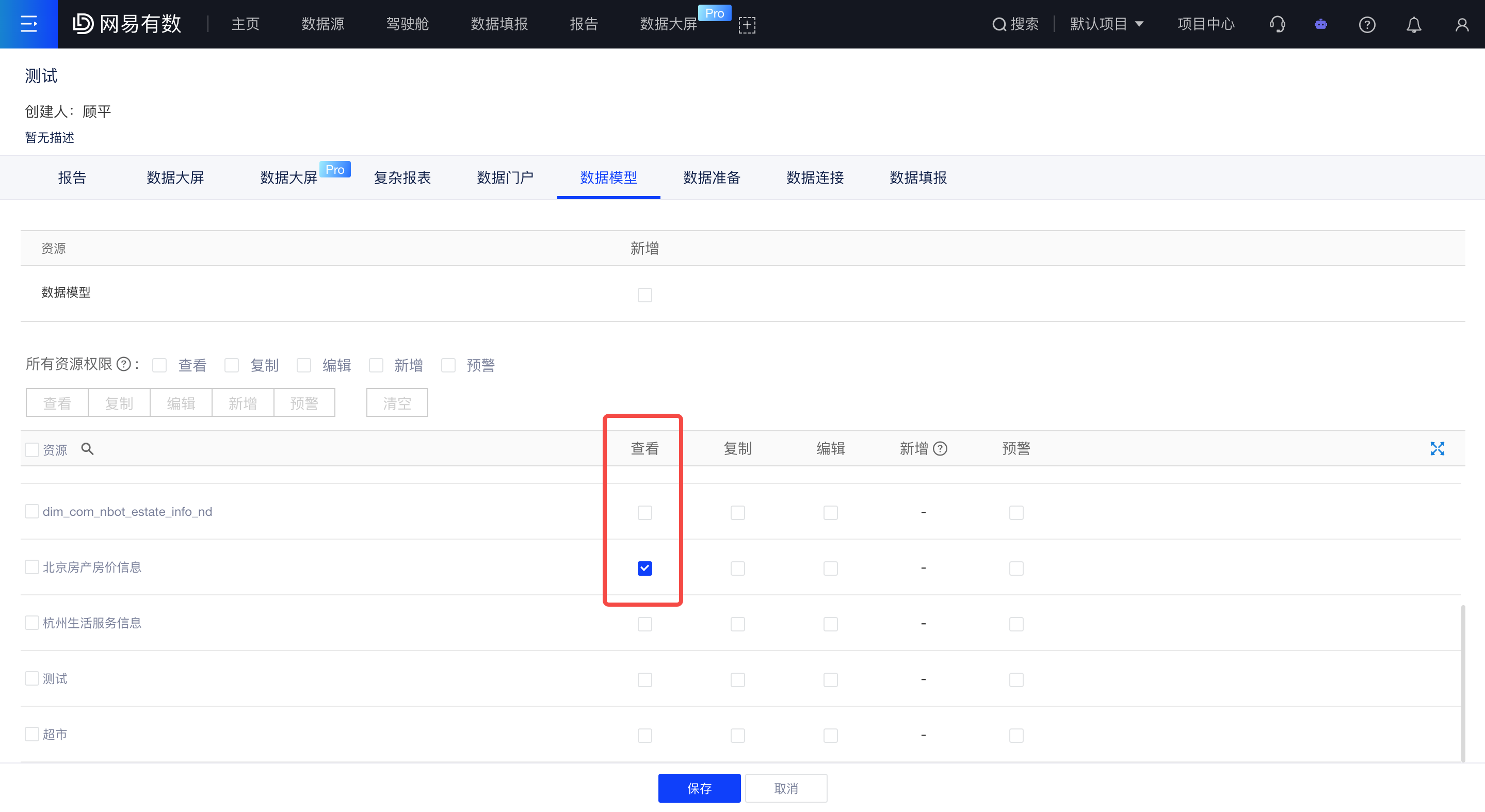
1.2 在角色管理中配置好角色并赋予用户
项目管理员在角色管理中,配置数据模型的查看权限,如下图,将配置好的角色赋予用户
2. 数据模型的易用性
为了让AI能准确识别数据表及字段的语义,也为了提升数据表对用户的可读性和易用性,项目管理员需要对数据模型进行以下优化:
2.1 模型名称
设置一个业务可理解的模型名称:数据模型的名称要能准确描述该模型中的数据,不建议采用无业务含义的模型名称,如“未命名模型”等。
2.2 字段设置
- 隐藏不必要的字段:比如「ID」、「修改时间」等对数据分析无用的字段。
- 对字段进行重命名:字段命名要让业务人员容易理解这个字段是什么,要通俗易懂,不要使用模凌两可的词语,也不要出现两个字段名称雷同。且字段名称不要使用特殊符号,比如:!、#、/、\、~等。
- 维度字段的成员定义:将维度字段的成员枚举值设置为更易理解的值,比如将性别字段中的“1”和“0”修改为“男”和“女”(可使用数据字典或计算字段功能)。
- 合理设置字段类型:比如将「订单日期」这种数据库中存储为字符串类型但实际业务含义为日期的字段转换为日期类型等。
- 合理分类维度和度量:比如将「客户ID」等数字型字段转成维度。
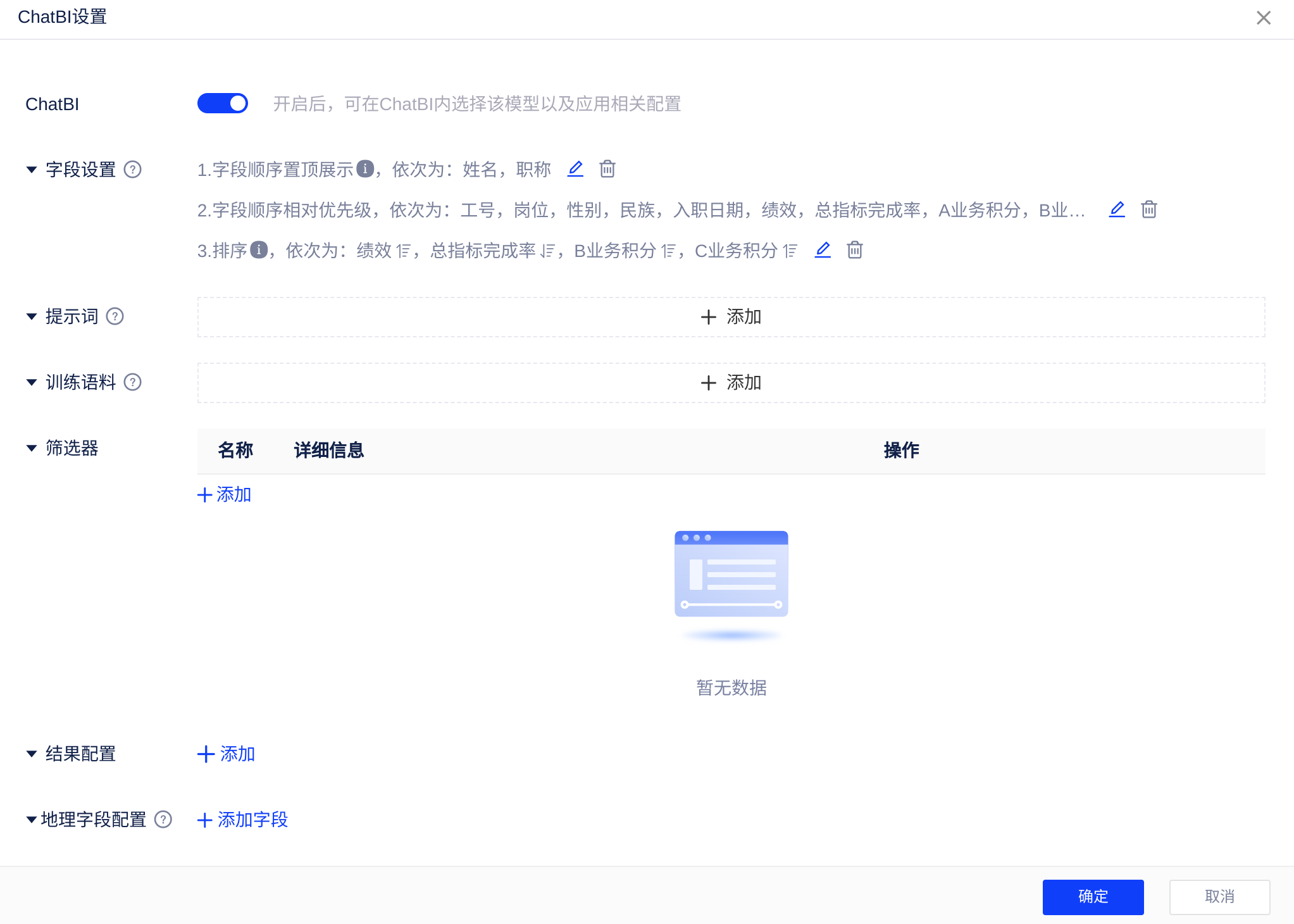
3.配置字段顺序与排序
宽表查询时,问答涉及多字段(如:查询员工绩效、入职时间、A业务积分、B业务积分、C业务积分、总指标完成率等)。当您需要以指定字段(如:姓名)为首列展示、或按照一定顺序展示字段可以通过[置顶展示]与[相对优先级]进行设置。同时可以在设置按照指定字段,如[总指标完成率]降序展示。
设置前
设置后
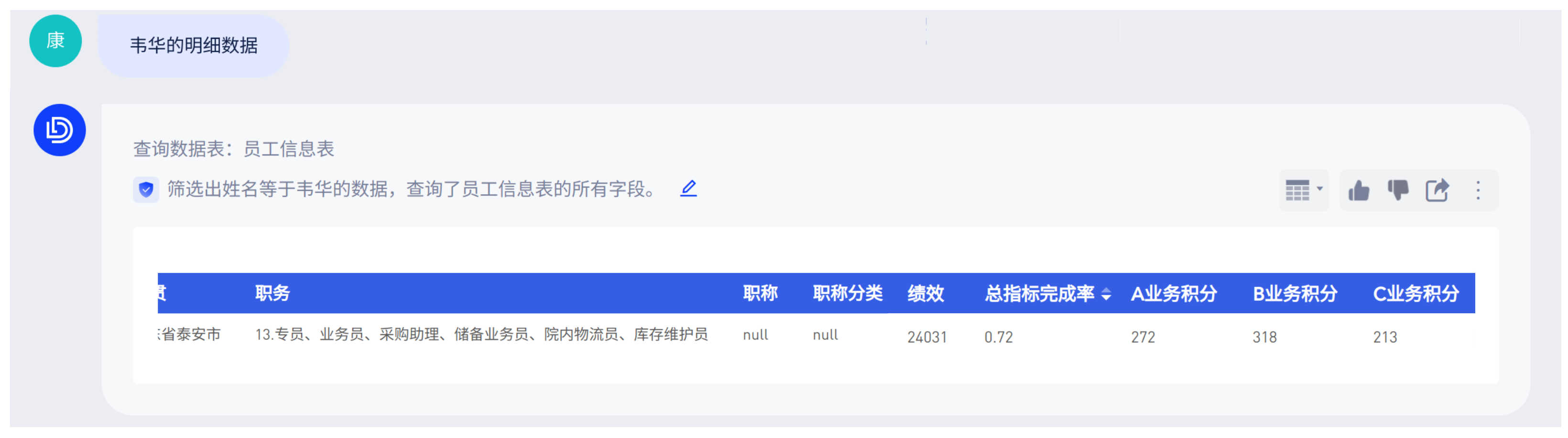
4. 配置行业知识
在实际使用的过程中,用户提问的时候会带入一些场景黑话和自己的提问习惯,而这些非通用的内容无法被大模型识别。但因大模型本身具备一定的自适应能力,建议在数据模型配置完成,选择应用于「ChatBI」后,先直接进行提问取数测试效果。如果感觉大模型对于特定业务及概念的理解不足,可再进行关键词的配置。
- 选择触发条件(什么情况下该提示词生效):目前支持「问题包含关键词」和「所有问题」两类触发条件(目前正在不断完善中,未来会支持更丰富的触发场景);
- 设置规则(提示词生效时,你希望AI大模型做什么):目前支持「自定义规则」和「选择字段」
目前提示词有如下限制:
- 每条问题最多只触发一个提示词规则;
- 填写提示词时,对数据模型中的字段值和字段名都用引号包裹,表示区分;
4.1 场景一
问题包含某些关键词时,让AI大模型按照用户设置的规则去查询,比如现在你要对员工信息进行分析,那么你需要根据企业内部的一些简称和习惯用语,对「员工信息表」做如下配置,让AI也能习得这些知识:
- 习惯用语一:市场部通常都是指代“市场营销部”
- 习惯用语二:技术岗指的是“岗位”为“工程师”
- 习惯用语三:职能部门指的是“财务审计部”或“人力资源部”
在提示词中,你可以配置问题包含的关键词,并选择「自定义规则」,输入具体的操作规则。
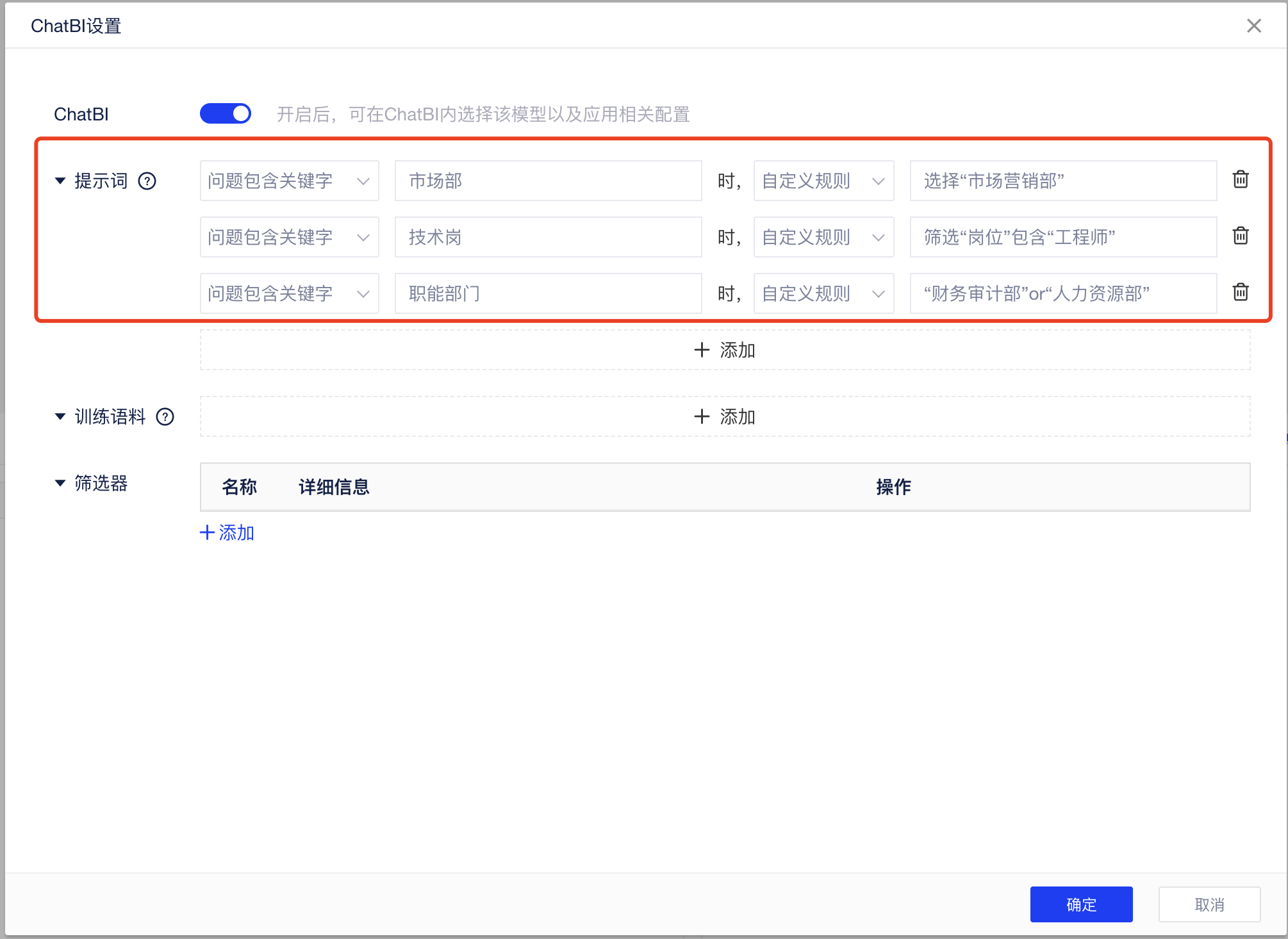
配置完成后,即可达到如下几个案例效果。
案例一
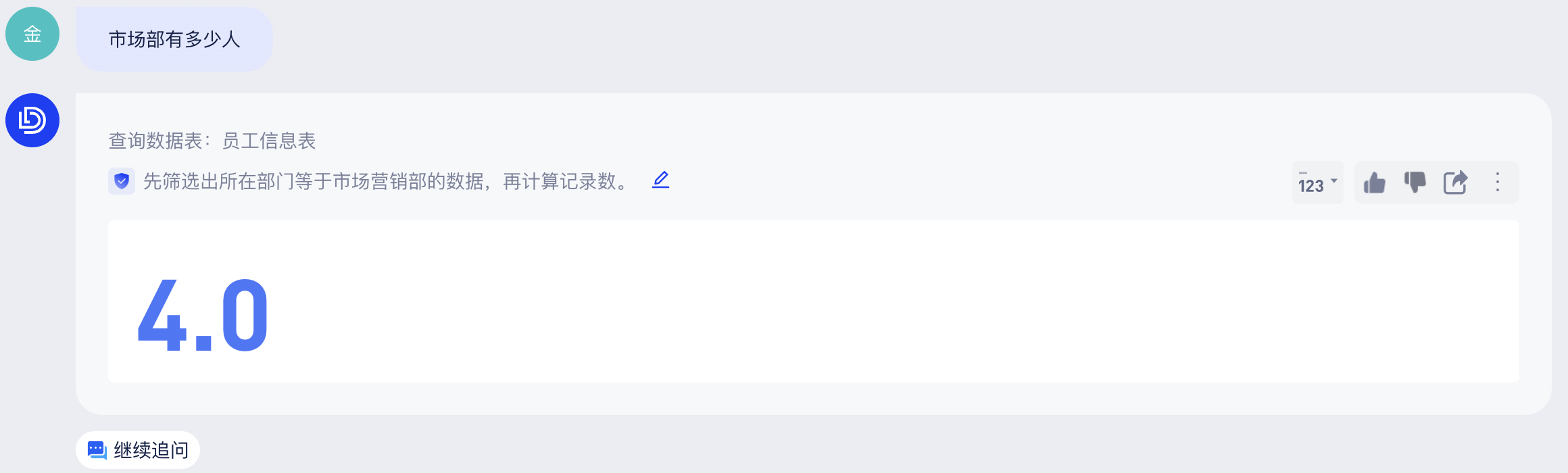
日常业务场景中,用户习惯于用“市场部”来指代“市场营销部”。当询问“市场部有多少人”的时候,大模型能够了解用户实际想询问“市场营销部有多少人”,查询部门为“市场营销部”的所有数据。
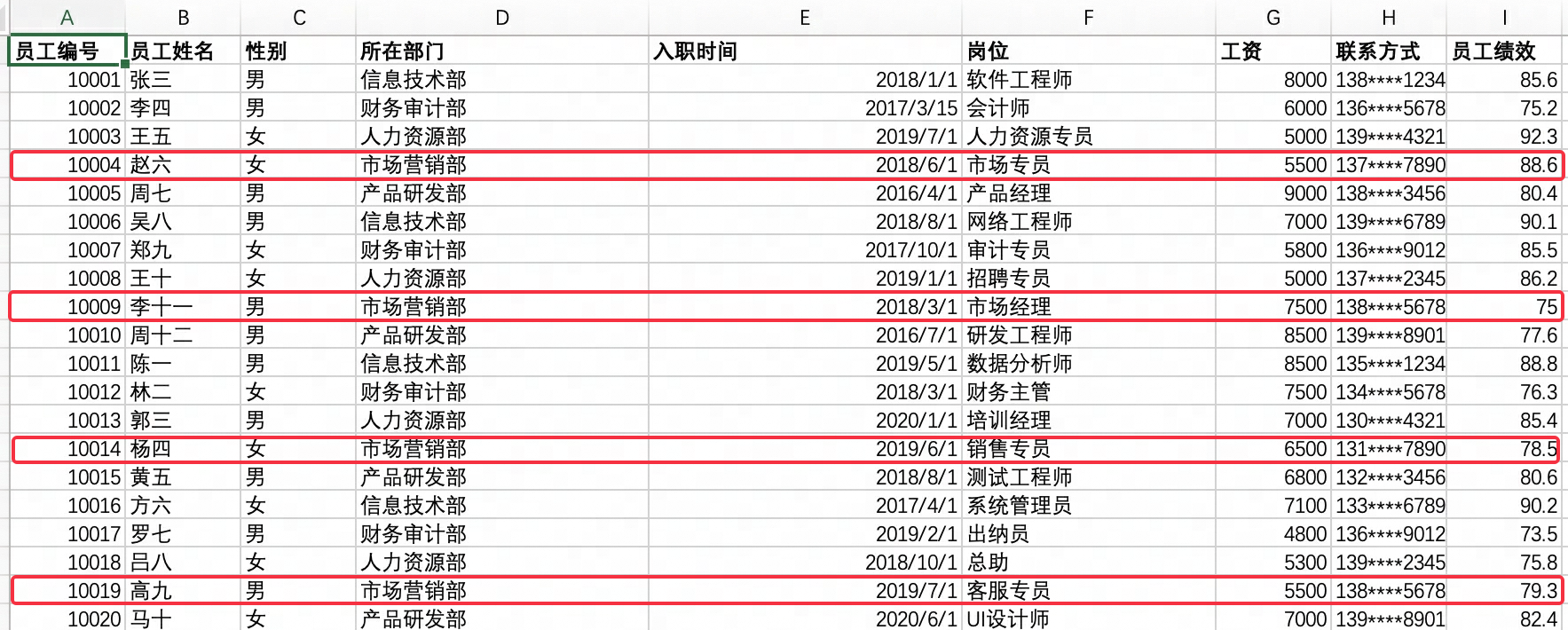
类似的案例在券商场景中也存在,比如用户一般习惯将”上海证券交易所”简称为“上交所”,但实际数据中并未含有“上交所”的相关内容。用户亦可以配置【上交所 = “上海证券交易所”】,让大模型能够更理解用户日常的表述习惯。
案例二
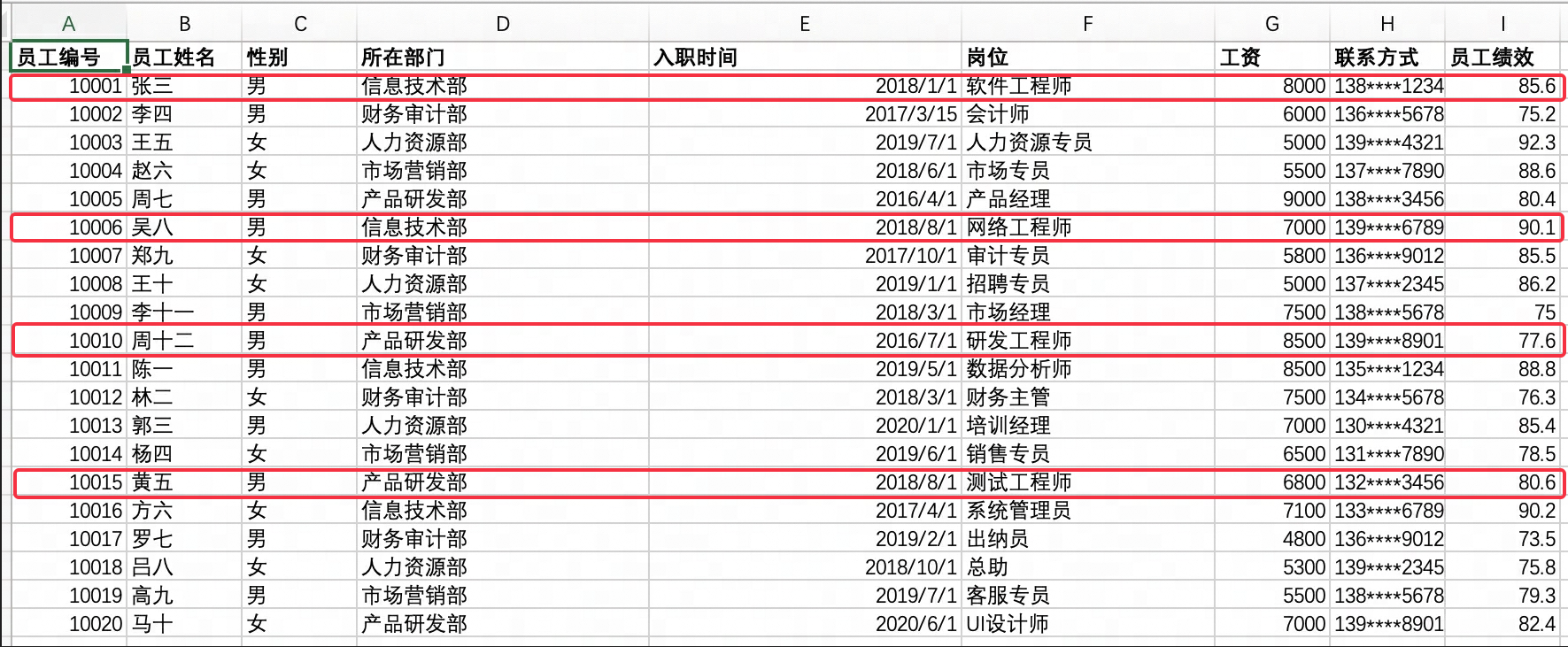
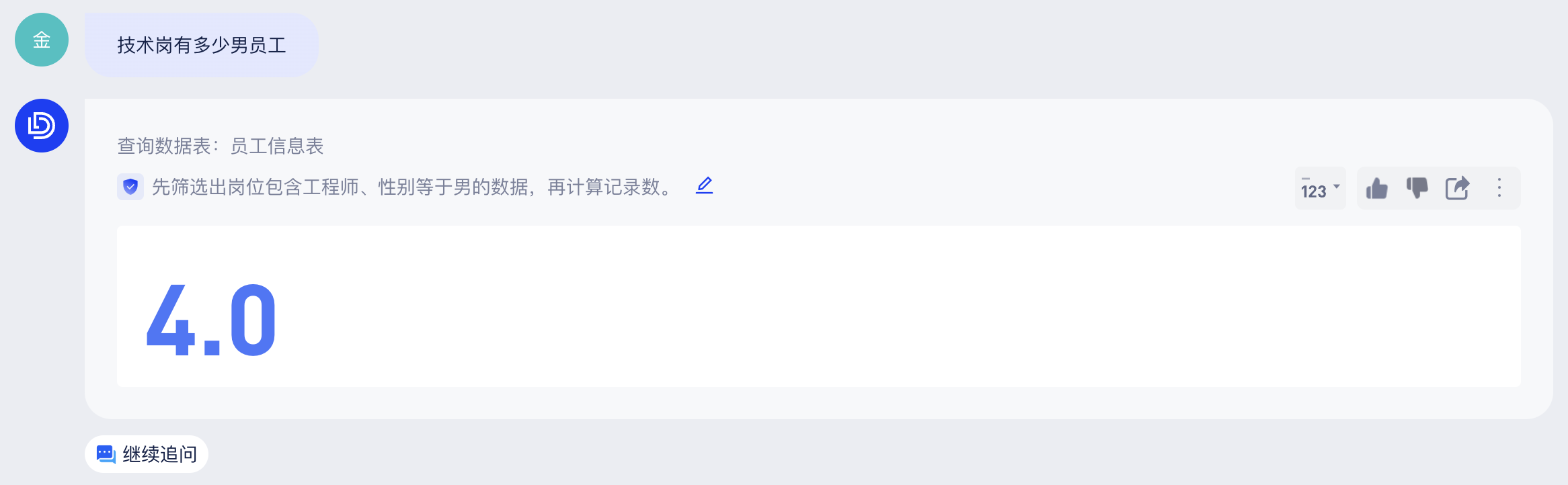
某些业务场景中,“技术岗”默认指代所有包含“工程师”的岗位。当用户提问“技术岗有多少男员工”,大模型可以如用户意图,查询“岗位名称包含工程师的员工中,性别为男的员工人数”。
案例三
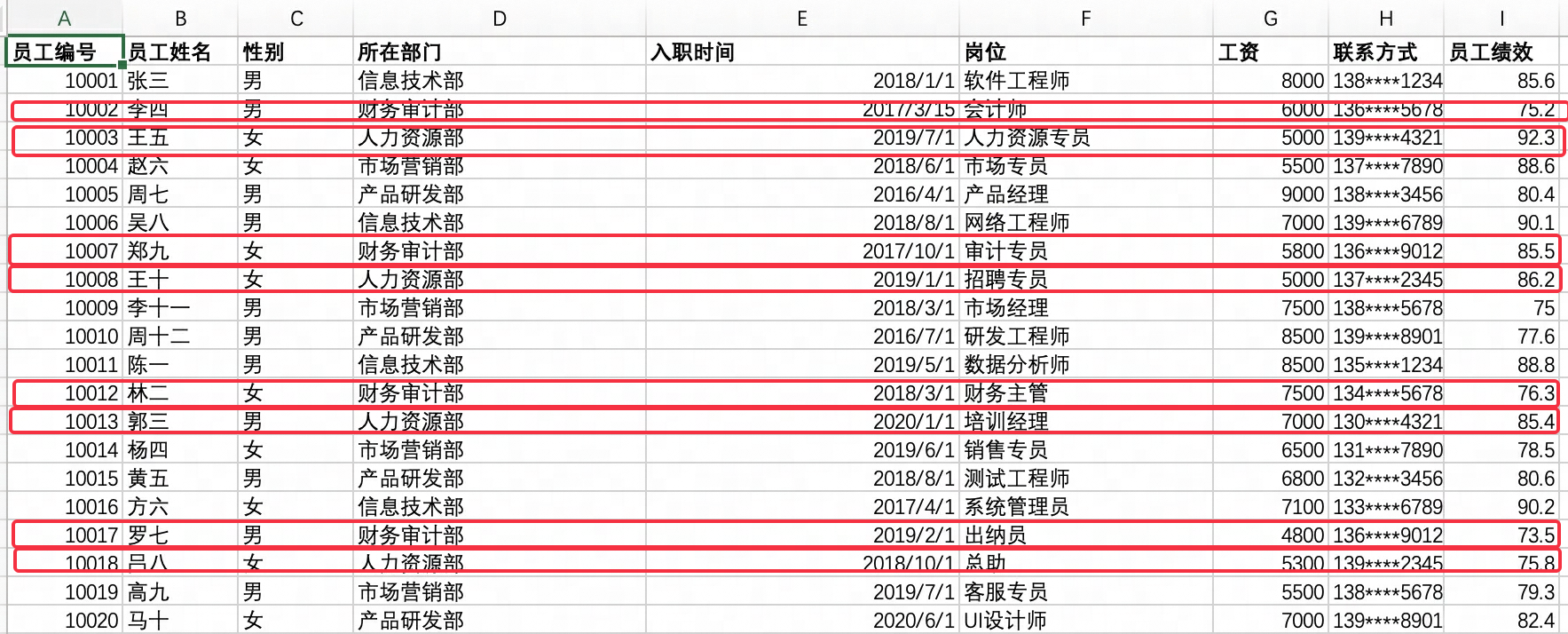
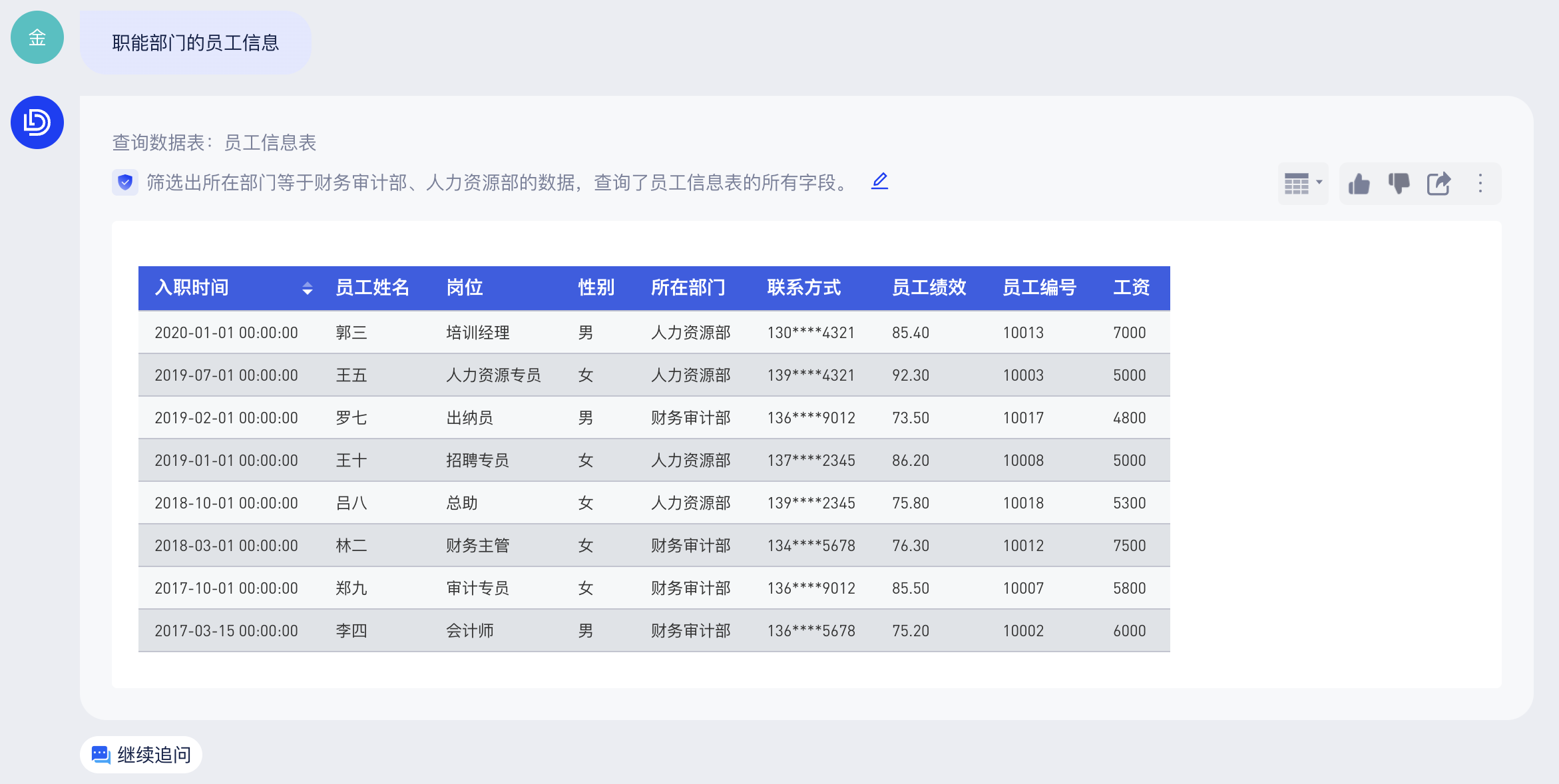
业务场景也会存在一些并集的情况,比如“财务审计部”和”人力资源部“都属于职能部门,当用户询问“职能部门”时,应当查询这两个部门的数据信息。
4.2 场景二
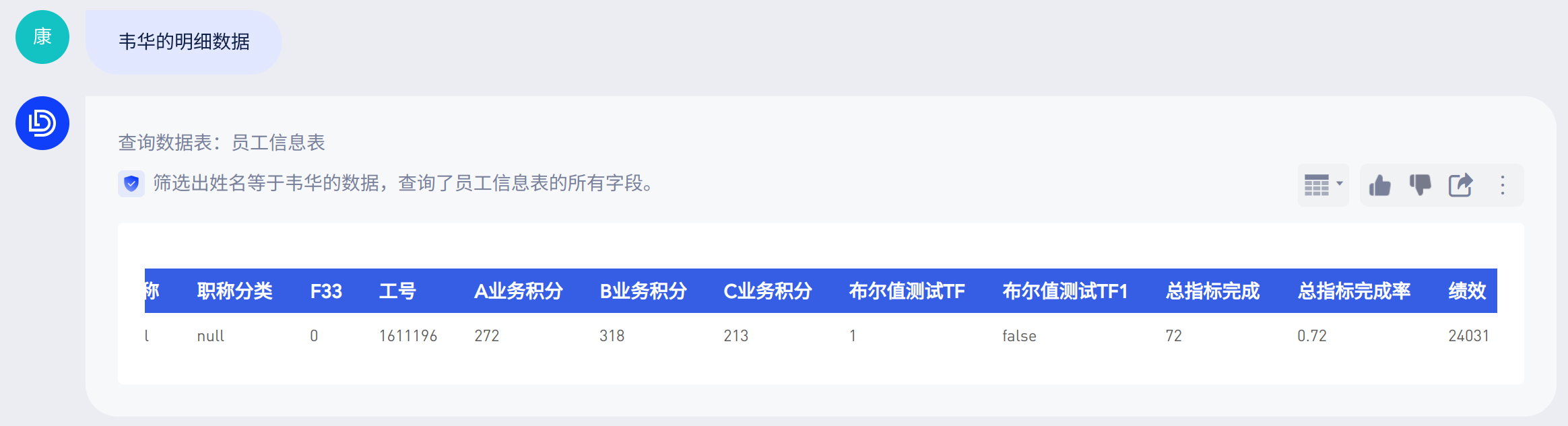
「人员信息表」中为人员的基础信息明细数据,如果你希望用户基于该表的问答均能带上「员工姓名」,那就可以设置提示词在“所有问题”均「选择字段」,然后在字段列表下拉选择“员工姓名”这个字段:
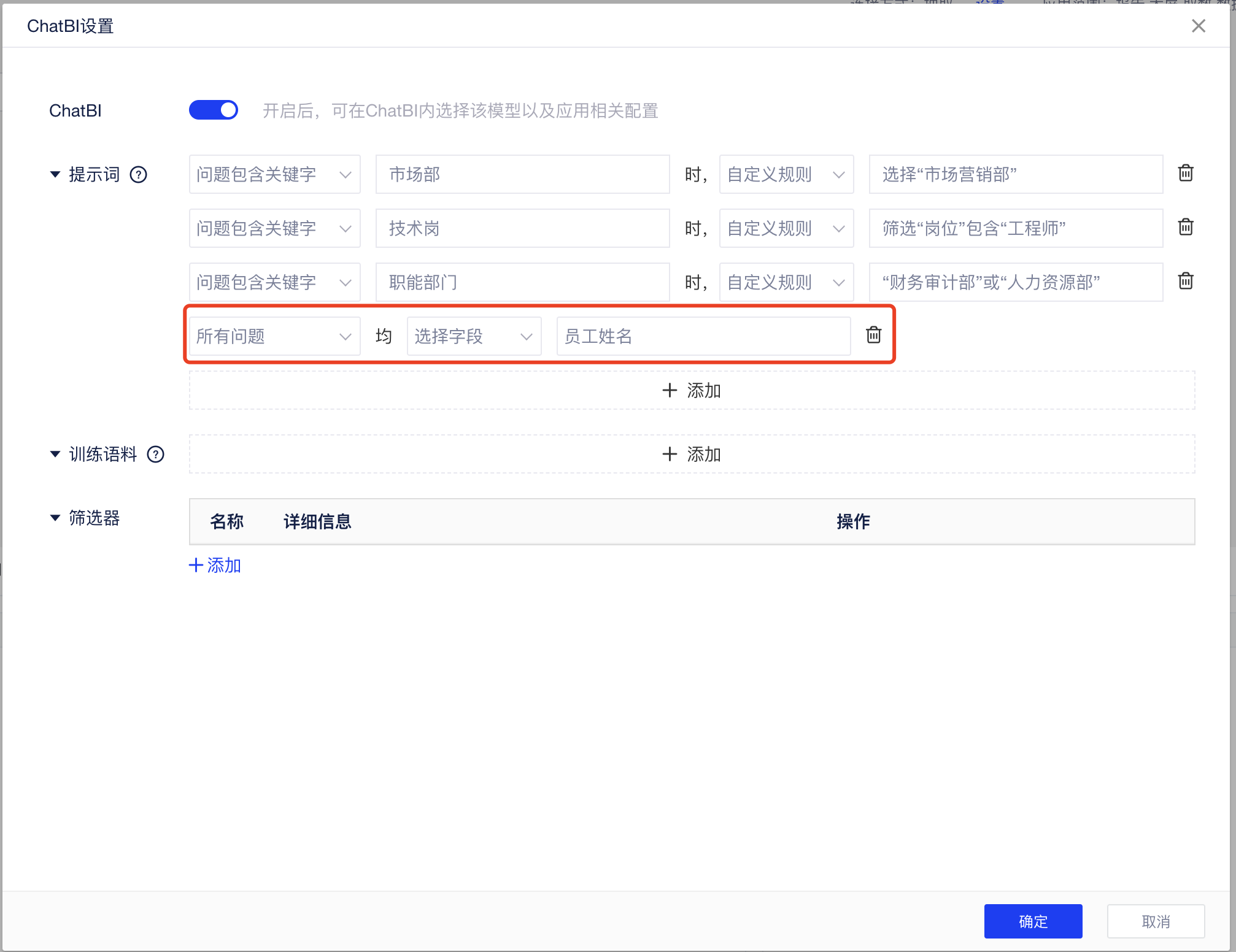
当你再次基于这个表格问问题“李四是哪个部门的”,可得到不一样的回答:
配置提示词之前
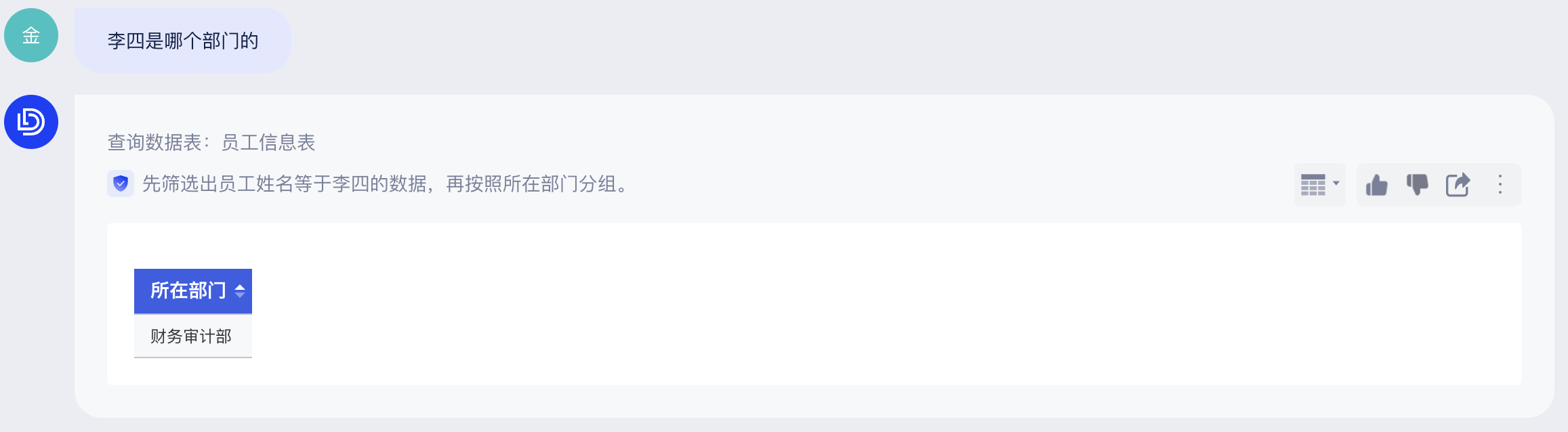
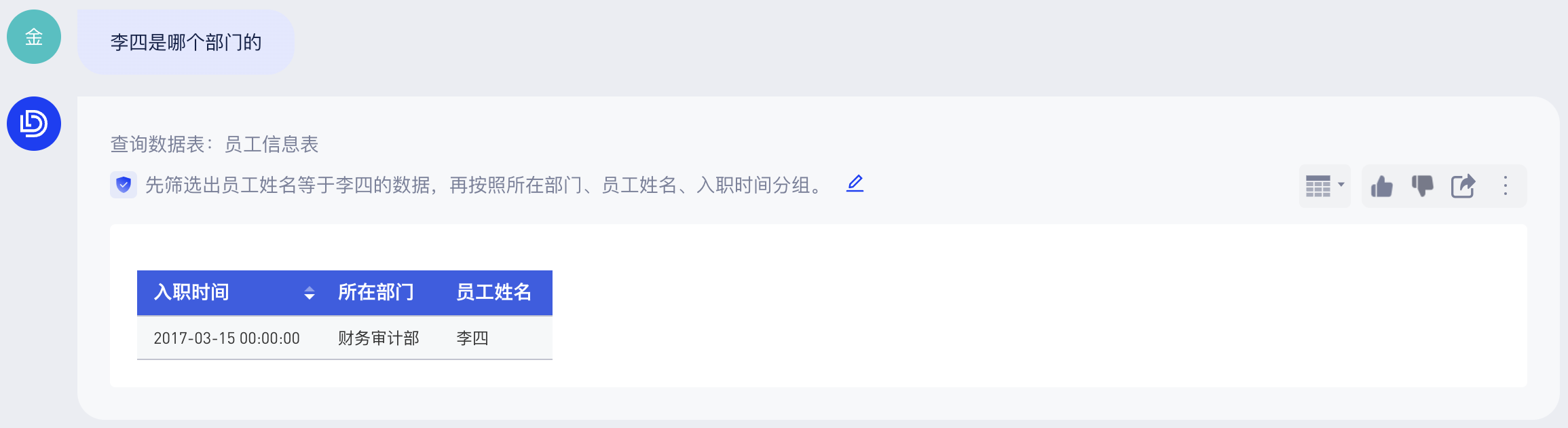
配置提示词之后
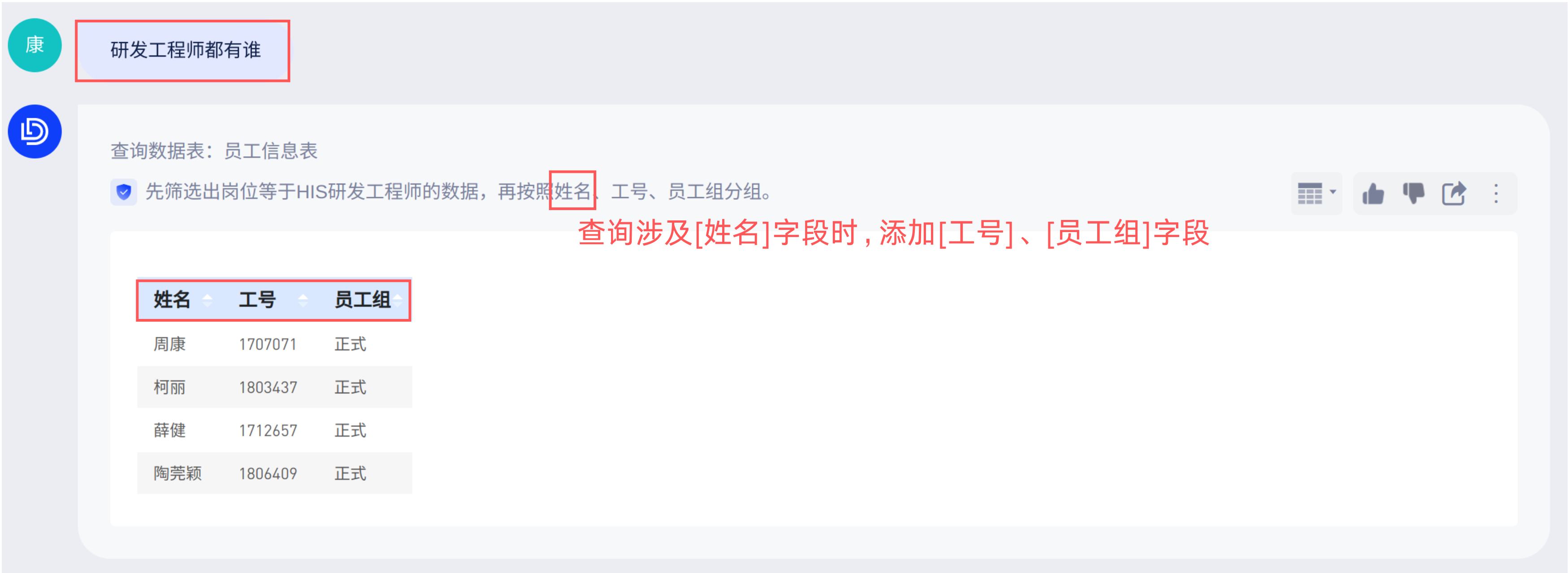
4.3 场景三
「人员信息表」包含人员的基础信息明细数据,当你查询“研发工程师都有谁”时,如果你希望当问题包含[员工姓名]时,同时展示[工号] 、[员工组]等信息以方便用户做对照。那就可以设置提示词在“问题包含字段”「工号」,“时,添加”「选择字段」然后在字段列表下拉选择“工号、员工组”字段:
- 配置界面

- 配置前:

- 配置后:
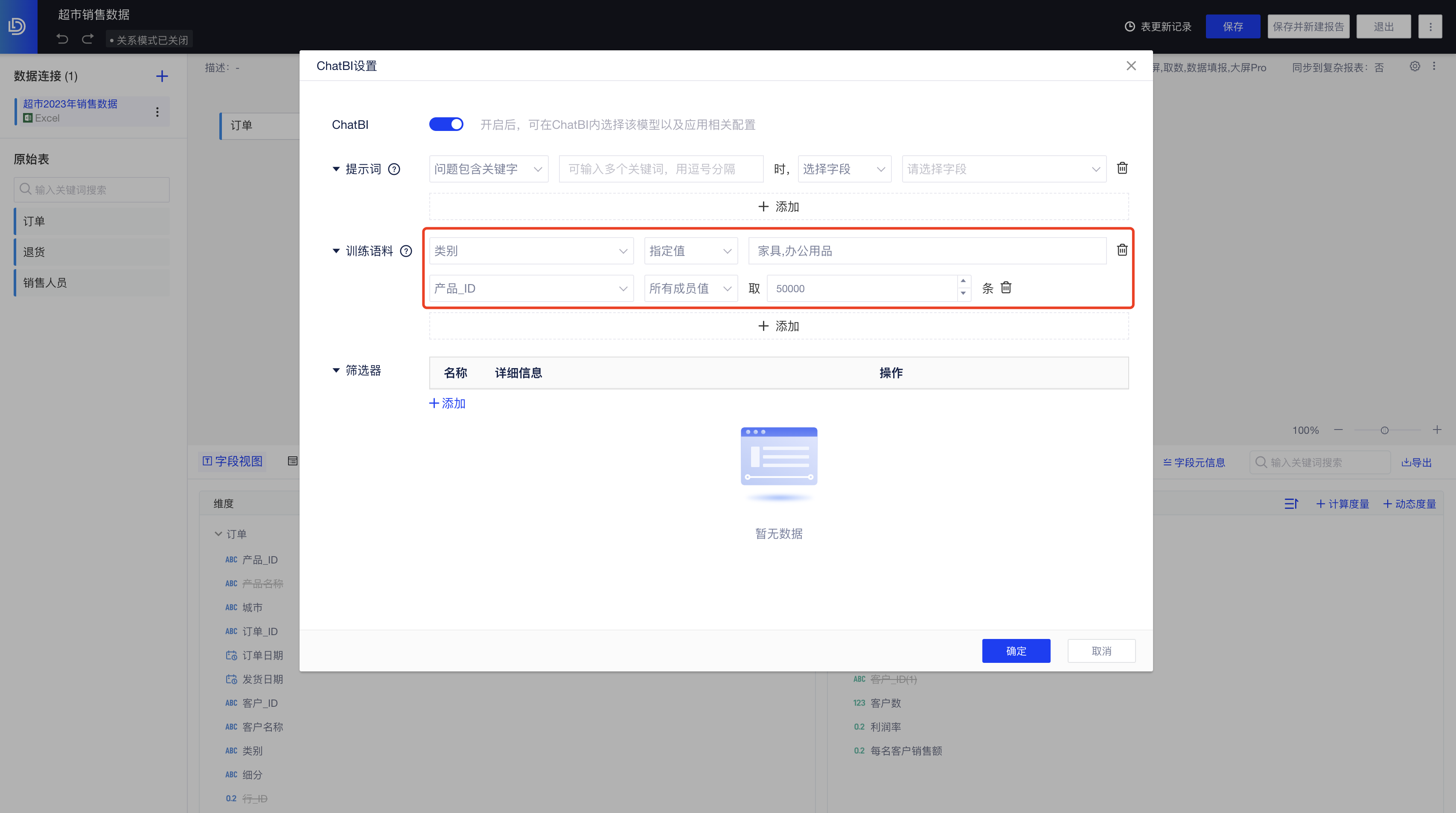
5. 配置训练语料
为了让AI大模型能更好地回答您的问题,您可以选择维度字段,提前设置训练语料,我们将自动缓存您所设置的维度成员值,AI将基于这些缓存数据进行预训练,以此提高问答准确率。以“超市销售数据”这个表为例:
- 对于可枚举的维度字段,如「类别」,可直接配置指定值,减少查询开销,提升性能;
- 对于不可枚举的字段,如「产品_ID」,可设置需要缓存的数据条数;
6. 配置地理字段
如果您需要在问答中绘制地图类,可在「地理字段配置」处添加字段。配置后包含该字段的回答才有可能绘制地图。
.png")
配置地理字段后,热力地图和标记地图类别可选:
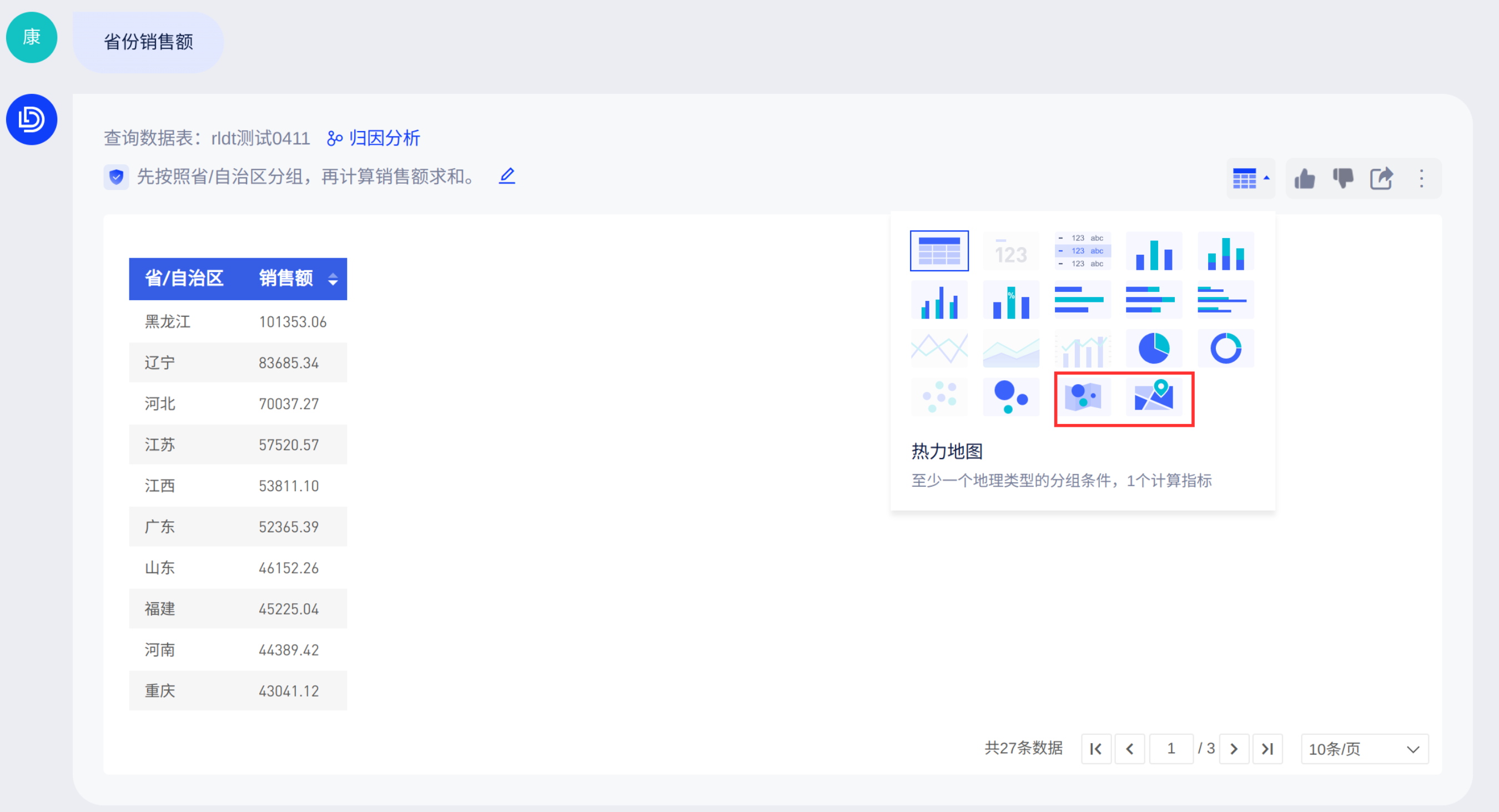
地图展示如下:
